Crawling data with Memorious
Memorious is the web crawling framework that is part of Aleph toolkit. It can be used to periodically retrieve structured and unstructured data from the web and load it into Aleph.
Memorious (named after Funes the Memorious) is a light-weight distributed web scraping toolkit. It can:
- Maintain an overview of a fleet of crawlers
- Scrape and store both structured and unstructured data from the web
- Load the scraped data to Aleph in a variety of ways
- Schedule crawler execution in regular intervals
- Store execution information and error messages
- Distribute scraping tasks across multiple machines
- Make crawlers modular and simple tasks re-usable
- Get out of your way as much as possible
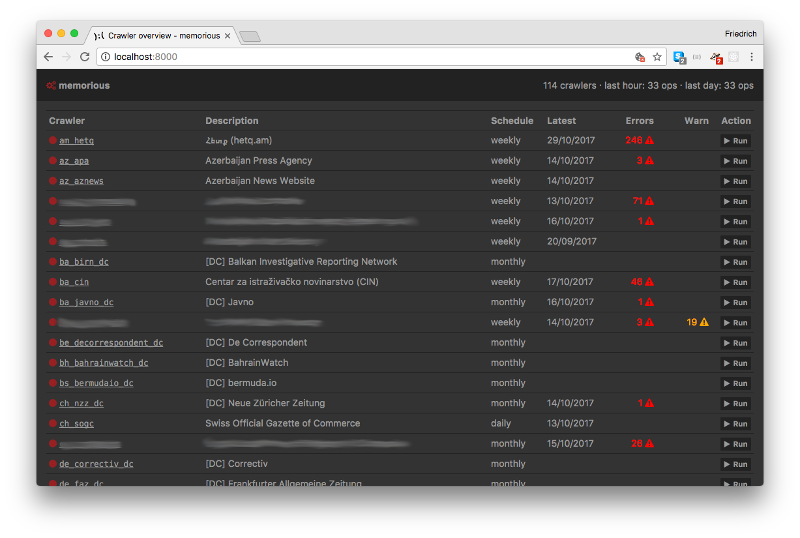
Memorious management interface
Memorious has a neat user interface to monitor the status of your crawler fleet at a glance. The interface also lets you start, stop and inspect crawlers with ease.
How it works
Memorious crawlers consist of a YAML configuration file and some (optional) Python functions to define crawler operations. Some built-in utility operations already come packaged with Memorious. For example, frequent operations like making HTTP requests, writing data into a database - can be done using built-in operations provided by Memorious. Memorious can also provide handy utilities to load the scraped data to Aleph for further processing.
A really simple crawler configuration in Memorious might look like this:
# Scraper for the OCCRP web site.
name: occrp_web_site
description: 'Organized Crime and Corruption Reporting Project'
# Uncomment to run this scraper automatically:
# schedule: weekly
pipeline:
init:
# This first stage will get the ball rolling with a seed URL.
method: seed
params:
urls:
- https://occrp.org
handle:
pass: fetch
fetch:
# Download the seed page
method: fetch
params:
# These rules specify which pages should be scraped or included:
rules:
and:
- domain: occrp.org
handle:
pass: parse
parse:
# Parse the scraped pages to find if they contain additional links.
method: parse
params:
# Additional rules to determine if a scraped page should be stored or not.
# In this example, we're only keeping PDFs, word files, etc.
store:
or:
- mime_group: archives
- mime_group: documents
handle:
store: store
# this makes it a recursive web crawler:
fetch: fetch
store:
# Store the crawled documents to a directory
method: aleph_emit
params:
collection: occrp_web_siteGetting started
To learn more about Memorious, you can:
- Visit the documentation available at https://alephdata.github.io/memorious/
- Explore and contribute to the source code
- Adapt the example project which includes some test crawlers and docker configuration.